24. Confidential RAG (and some other AI use cases) on GCP
While I worked at Google during the publishing of this post / video, the views expressed here are my own and may not reflect those of my employer. Only publicly available material is used to put together the content of this article and video. The website and the Youtube videos are NOT monetized.
💡 For most customers, it is recommended that they use Google’s Vertex AI capabilities to implement Retrieval Augmented Generation (RAG) and other AI use cases. The approach from this post is recommended when the customers have very restrictive data protection mandates or compliances. These customers generally fall in category of sovereign customers (public sector, critical national infrastructure, customers restricted to their own models etc.).
You can directly scroll down to the Demo Video. And since the video is extremely detailed one, I am keeping the blog post very brief.
AI is no longer a novelty but a necessity today, every organization is harnessing its power. AI is transforming businesses, streamlining operations, and driving innovation.
Among the myriad of AI applications, Natural Language Processing (NLP), and more specifically, the Retrieval-Augmented Generation (RAG - explained in the video below), is emerging as one of the dominant use cases.
However, for public sector entities and critical infrastructure providers, data protection concerns may arise when using public AI APIs. Some of them might also be restricted to use their own (or open source) AI models.
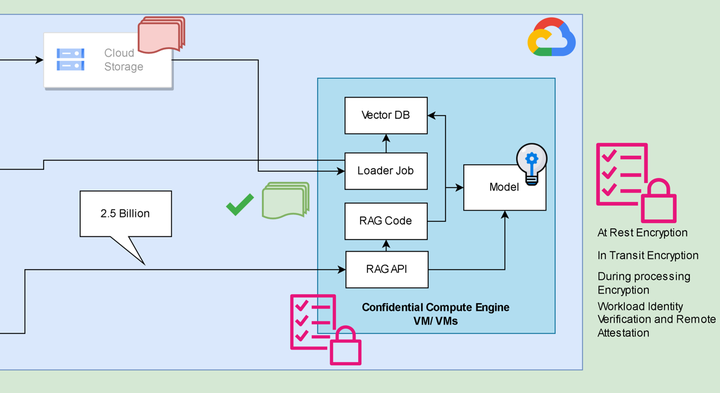
The solution? Running their own RAG and other AI use cases on confidential Virtual Machines (VMs) powered by Google Cloud and Google Cloud’s Ubiquitious Data Encryption (UDE).
In short, the confidential compute VMs ensure encryption of data in use viz. have their RAM encrypted and UDE assures that your data lands and processes, “end to end” encrypted on a confidential VM only.
This approach offers the following assurances
- Customer controlled external encryption at rest (for training data, model weights).
- Encryption in transit (Inference queries and responses)
- Encryption during processing (RAM loaded model and inference operations)
- The workload is running on a securely booted confidential VM with encrypted RAM and the training data is delivered and processed only on a confidential VM.
This approach ensures data privacy, allowing these organizations to reap the benefits of AI without compromising on various data protection compliances and regulations even when they are overly restrictive.
Such customers can also use this approach for other AI use cases like
- Fine tuning a model using proprietary/ patented data to add behaviors
- Setting up confidential AI/ML pipelines for both NLP and NON NLP tasks (One such use case is also demonstrated here)
- Fine tuning their own model on proprietary data and running inferences
All right 🤟! the following video -
- Explains RAG
- Demos confidential RAG
- Explains and demos other confidential AI use case implementations (e.g. confidential speech to text ML pipeline)
Video Demo
Please watch in full screen or on Youtube directly
For a more detailed explanation of Google Cloud’s UDE capability you can also refer to this post. And this post can help you with the setup.
Conclusion
While most customers can (and should) actually use Google’s Vertex AI capabilities, customers who exhibit an elevated concern for data privacy and confidentiality - can use Google’s confidential compute with UDE to implement AI use cases that otherwise cannot be implemented using API based AI offerings.
Thank you for reading through, Please like 👍, share 🔗 and comment ✍ if you found it useful.
-Nikhil
Further reading / listening
- Google Cloud - Confidential Computing
- 📽 Trust the cloud more by trusting it less: Ubiquitous data encryption
- Vertex AI | Google Cloud
- 18. Sovereignty Part 2/4 - Encryption to power data sovereignty on Google Cloud (Demo GCP EKM + KAJ and Confidential computing)
- google/flan-t5-small
- Narsil/asr_dummy
- ChromaDB - 🧪 Usage Guide
- 20. Sovereignty Part 4/4 - Setting up sovereignty demo on GCP - Google cloud EKM + Confidential Computing + Ubiquitous Data Encryption/UDE + Thales CKM
- What 🤗 Transformers can do